
Introduction
SQL Server 2005 now offers the possibility to partition tables and indexes. Using this feature can boost your DWH load. It will not necessarily enhance your query performance, but it will make the typical tasks of loading the DWH DB easier.
If you are not familiar with partitioning in SQL Server 2005, take a look at this mind map; it provides a good overview.
Let's take a look at an example: Assume we want to import revenue files that are delivered monthly using flat files:
1000;PROD_1;1750
1000;PROD_2;2345
1100;PROD_1;2000
...
The period (year and month) can be read from the file name (RevenueYYYYMM.txt). We want to read the revenue files into a revenue table that is partitioned by period. It should be possible to load a month more than once. If a month's revenue data is delivered more than once, the appropriate partition should be deleted as fast as possible. Therefore, we will not use a simple
Delete statement.
The first step is the creation of the paritioned table:
CREATE PARTITION FUNCTION RevenuePartitionFunction ( int )
AS RANGE RIGHT FOR VALUES ( 200501 );
CREATE PARTITION SCHEME RevenuePartitionScheme
AS PARTITION RevenuePartitionFunction ALL TO ( [PRIMARY] );
CREATE TABLE Revenue
( Period int, CustomerID int, ProductID varchar(10), Revenue money )
ON RevenuePartitionScheme ( Period );
We need a helper table for dropping a whole period:
CREATE TABLE ImportHelper
( Period int, CustomerID int, ProductID varchar(10), Revenue money );
Before we can start to create the appropriate SSIS package for importing data, we create a Stored Procedure that handles the creation of partitions:
create procedure PreparePeriodForLoading
@Period int
as
declare @PartitionId int;
-- check if partition for this period already exists
select @PartitionId = rv.boundary_id + 1
from sys.partition_functions pf
inner join sys.partition_range_values rv on pf.function_id=rv.function_id
where pf.name='RevenuePartitionFunction'
and rv.value=@Period;
if @PartitionId is not null begin
-- partition already exists; switch partition content into ImportHelper-table
truncate table dbo.ImportHelper;
alter table Revenue switch partition @PartitionId to ImportHelper;
truncate table dbo.ImportHelper;
end else begin
-- partition does not exist; create it.
alter partition scheme RevenuePartitionScheme
next used [PRIMARY];
alter partition function RevenuePartitionFunction()
split range ( @Period );
end
Now we can create the SSIS-Package for importing data. It consists of a
ForEach loop iterating over all import files. Inside the loop, we use a SSIS script task to extract the PeriodId from the file name, we call the procedure shown above, and import the data from the flat file: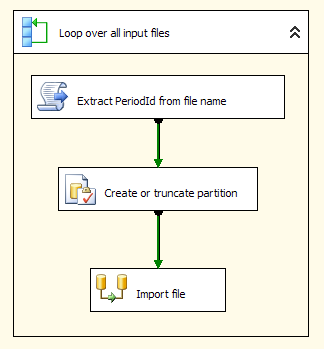
Here is the code for the script task (don't forget to specify
ReadOnlyVariables and ReadWriteVariables in the Script Task Editor Property Window):Imports System
Imports System.Data
Imports System.Math
Imports Microsoft.SqlServer.Dts.Runtime
Public Class ScriptMain
Private Const FilePrefix As String = "\Revenue"
Public Sub Main()
Dim FileNameString As String
FileNameString = Dts.Variables("FileName").Value.ToString()
Dts.Variables("Period").Value = _
Convert.ToInt32(FileNameString.Substring(FileNameString.LastIndexOf("\") + _
FilePrefix.Length, 6))
Dts.TaskResult = Dts.Results.Success
End Sub
End Class
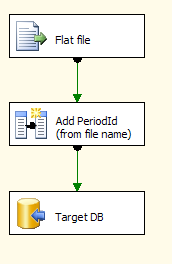
This is how the data flow looks like; quite straightforward:
No comments:
Post a Comment