
Informatica Interview Questions...
Quite ridiculous, but that is how it is...People are never
satisfied..After a switch, people are again thinking of another..
Some how today I felt it again...but question came in my mind, my I ready for it? What questions interviewer will ask and what had been asked last time, which I could not answer? I had gone through the Informatica manuals so every theoretical questions I could answer confidently, but there was a problem with scenario based questions... Somehow today I recollecting those and doing the practice at home. Kudos to Chand and Ameerpeth, because of them I have Informatica 8.6 installed on my PC.
Last Interview which I had given was of CTS, there were some questions which I could not answer properly..below are those
1. How will you transpose rows from one table to 2 target tables wherein 1 target will have all odd rows and another target will have all even rows.

Image might not properly visible, but then also you can make ouut from colors...
As required, taken 2 separate instances of one target, one source, router for dividing the odd and even rows. You require sequence generator in such cases so I added.
Logic -- pretty simple
 As you can see, 2
groups odd and even created at group and conditions MOD(NEXTVAL,2) != 0 and
MOD(NEXTVAL,2) = 0 added respectively for those groups. Depending upon value of
sequence generator (NESTVAL) rows will get routed from router to odd and even
targets.
As you can see, 2
groups odd and even created at group and conditions MOD(NEXTVAL,2) != 0 and
MOD(NEXTVAL,2) = 0 added respectively for those groups. Depending upon value of
sequence generator (NESTVAL) rows will get routed from router to odd and even
targets.
Below is the result

2nd Question -- This was quite tough [at least for me] than the previous one.
Split the records in a table wherein first half part with go to one table and second half part will go to another table.
Solution --> Here I split the task into 2 sessions. First session will count the number of records and another session will use those counts and split the actual records.
First session -->
You need to have mapping variable to store the value. I faced number of difficulties while storing a value to mapping variable.
There are 3 functions by which you can assign a value to mapping variable.
SETVARIABLE --
Some how today I felt it again...but question came in my mind, my I ready for it? What questions interviewer will ask and what had been asked last time, which I could not answer? I had gone through the Informatica manuals so every theoretical questions I could answer confidently, but there was a problem with scenario based questions... Somehow today I recollecting those and doing the practice at home. Kudos to Chand and Ameerpeth, because of them I have Informatica 8.6 installed on my PC.
Last Interview which I had given was of CTS, there were some questions which I could not answer properly..below are those
1. How will you transpose rows from one table to 2 target tables wherein 1 target will have all odd rows and another target will have all even rows.

Image might not properly visible, but then also you can make ouut from colors...
As required, taken 2 separate instances of one target, one source, router for dividing the odd and even rows. You require sequence generator in such cases so I added.
Logic -- pretty simple
 As you can see, 2
groups odd and even created at group and conditions MOD(NEXTVAL,2) != 0 and
MOD(NEXTVAL,2) = 0 added respectively for those groups. Depending upon value of
sequence generator (NESTVAL) rows will get routed from router to odd and even
targets.
As you can see, 2
groups odd and even created at group and conditions MOD(NEXTVAL,2) != 0 and
MOD(NEXTVAL,2) = 0 added respectively for those groups. Depending upon value of
sequence generator (NESTVAL) rows will get routed from router to odd and even
targets.Below is the result

2nd Question -- This was quite tough [at least for me] than the previous one.
Split the records in a table wherein first half part with go to one table and second half part will go to another table.
Solution --> Here I split the task into 2 sessions. First session will count the number of records and another session will use those counts and split the actual records.
First session -->
You need to have mapping variable to store the value. I faced number of difficulties while storing a value to mapping variable.
There are 3 functions by which you can assign a value to mapping variable.
SETVARIABLE --
Sets the current value of a mapping variable to a
value you specify. Returns the specified value. The SETVARIABLE function
executes only if a row is marked as insert or update. SETVARIABLE ignores all
other row types and the current value remains unchanged.
At the end of a successful session, the Integration
Service compares the final current value of the variable to the start value of
the variable. Based on the aggregate type of the variable, it saves a final
current value to the repository. Unless overridden, it uses the saved value as
the initial value of the variable for the next session run.
Use the SETVARIABLE function only once for each
mapping variable in a pipeline. The Integration Service processes variable
functions as it encounters them in the mapping. The order in which the
Integration Service encounters variable functions in the mapping may not be the
same for every session run. This may cause inconsistent results when you use
the same variable function multiple times in a mapping.
SETMAXVARIABLE --
Sets the current value of a mapping variable to the
higher of two values: the current value of the variable or the value you
specify. Returns the new current value. The function executes only if a row is
marked as insert. SETMAXVARIABLE ignores all other row types and the current
value remains unchanged.
At the end of a successful session, the Integration
Service saves the final current value to the repository. When used with a
session that contains multiple partitions, the Integration Service generates
different current values for each partition. At the end of the session, it
saves the highest current value across all partitions to the repository. Unless
overridden, it uses the saved value as the initial value of the variable for
the next session run.
When used with a string mapping variable,
SETMAXVARIABLE returns the higher string based on the sort order selected for
the session.
Use the SETMAXVARIABLE function only once for each
mapping variable in a pipeline. The Integration Service processes variable
functions as it encounters them in the mapping. The order in which the
Integration Service encounters variable functions in the mapping may not be the
same for every session run. This can cause inconsistent results when you use
the same variable function multiple times in a mapping.
SETMINVARIABLE--
Sets the current value of a mapping variable to the
lower of two values: the current value of the variable or the value you
specify. Returns the new current value. The SETMINVARIABLE function executes
only if a row is marked as insert. SETMINVARIABLE ignores all other row types
and the current value remains unchanged.
At the end of a successful session, the Integration
Service saves the final current value to the repository. When used with a session
that contains multiple partitions, the Integration Service generates different
current values for each partition. At the end of the session, it saves the
lowest current value across all partitions to the repository. Unless
overridden, it uses the saved value as the initial value of the variable for
the next session run.
When used with a string mapping variable,
SETMINVARIABLE returns the lower string based on the sort order selected for
the session.
Use the SETMINVARIABLE function only once for each
mapping variable in a pipeline. The Integration Service processes variable
functions as it encounters them in the mapping. The order in which the
Integration Service encounters variable functions in the mapping may not be the
same for every session run. This may cause inconsistent results when you use
the same variable function multiple times in a mapping.
Above information have been taken directly from Help files, you can read
more if you are interested.
As stated above,
1. your mapping should have one target
2.Mapping should be completed without errors
3. Row should be of Insert Type [ as I have used setMaxVariable]
4. Aggregation type should be Max
[
Here, if at function you are using setMaxVariable and at mapping variable level if you choose min as aggregate type then you will get below error. and mapping will become invalid.
Parsing mapping m_InterviewQ2...
Transformation: exp_Assign_Count Field: V_Assign
<> [SETMAXVARIABLE]: function cannot be used for min aggregate type mapping variable.
... SETMAXVARIABLE(>>>>$$RecordCnt<<<<,O_RecordCount)
...there are parsing errors.
]
5. IsExpVariable should be FALSE [ I do not know what is it]
I struggled a bit while creating this setup and storing a value at mapping variable.
 One very IMP thing
is, as in an image above, you have to connect a port where you have assign a
value to mapping variable to target. Otherwise that function [in this case
SetMaxVariable] will not get executed and mapping variable will not get assign
any value.
One very IMP thing
is, as in an image above, you have to connect a port where you have assign a
value to mapping variable to target. Otherwise that function [in this case
SetMaxVariable] will not get executed and mapping variable will not get assign
any value.
 Once you run the
workflow, check if its getting completed without any errors or not.
Once you run the
workflow, check if its getting completed without any errors or not.
How will you check the mapping variable value? Just right click on your session, where your mapping is defined - click on "view persistent value" and new window will appear with mapping variable and its value.


This only the half task is done; We have retrieved total count of the table, which we have to use in second mapping to divide the rows in 2 parts.
We will follow below procedure to execute this thing
1. Create a new mapping; Declare a $RC mapping variable in it.
2. Create new Seq Transformation and use that in Expression to count current row number.
3. Create new Router and create 2 groups in it a. FirstHalf b. SecondHalf
4. Use logic as $$RC/2 <= NEXTVAL and $$RC/2 > NEXTVAL inside those groups resp.
5. Connect those groups to target instances.

Now the main challenge is to get the RecordCount of previous session to new mapping variable.
Informatica 8.6 has facility wherein you can assign value of Workflow Variable to Mapping Variable and vice versa.
In first session, at components tab there is an option "Post session on successful variable assignment" where we have assigned value of Mapping Variable to Workflow Variable.
In second session, at components tab there is an option "Pre session variable assignment" where we have assigned value of workflow variable to another mappings mapping variable. This is how, we have assigned a value of one mapping variable in mapping 1, to another mapping variable in second mapping.


As stated above,
1. your mapping should have one target
2.Mapping should be completed without errors
3. Row should be of Insert Type [ as I have used setMaxVariable]
4. Aggregation type should be Max
[
Here, if at function you are using setMaxVariable and at mapping variable level if you choose min as aggregate type then you will get below error. and mapping will become invalid.
Parsing mapping m_InterviewQ2...
Transformation: exp_Assign_Count Field: V_Assign
<> [SETMAXVARIABLE]: function cannot be used for min aggregate type mapping variable.
... SETMAXVARIABLE(>>>>$$RecordCnt<<<<,O_RecordCount)
...there are parsing errors.
]
5. IsExpVariable should be FALSE [ I do not know what is it]
I struggled a bit while creating this setup and storing a value at mapping variable.
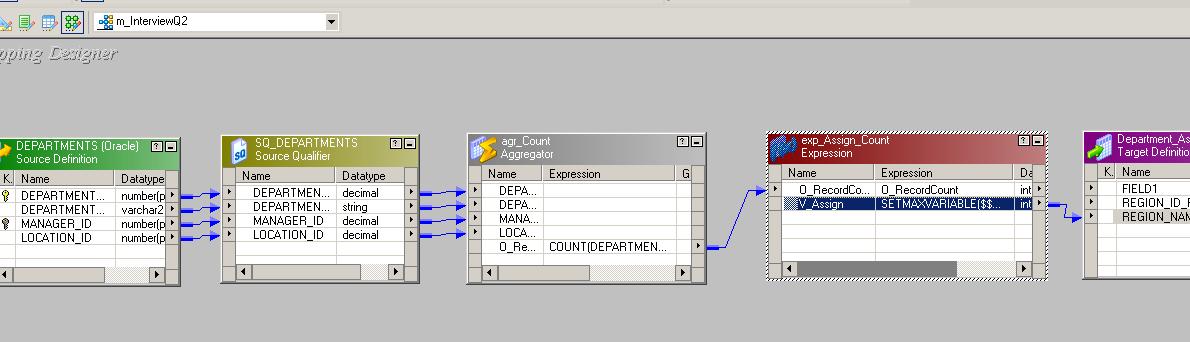 One very IMP thing
is, as in an image above, you have to connect a port where you have assign a
value to mapping variable to target. Otherwise that function [in this case
SetMaxVariable] will not get executed and mapping variable will not get assign
any value.
One very IMP thing
is, as in an image above, you have to connect a port where you have assign a
value to mapping variable to target. Otherwise that function [in this case
SetMaxVariable] will not get executed and mapping variable will not get assign
any value. Once you run the
workflow, check if its getting completed without any errors or not.
Once you run the
workflow, check if its getting completed without any errors or not.How will you check the mapping variable value? Just right click on your session, where your mapping is defined - click on "view persistent value" and new window will appear with mapping variable and its value.


This only the half task is done; We have retrieved total count of the table, which we have to use in second mapping to divide the rows in 2 parts.
We will follow below procedure to execute this thing
1. Create a new mapping; Declare a $RC mapping variable in it.
2. Create new Seq Transformation and use that in Expression to count current row number.
3. Create new Router and create 2 groups in it a. FirstHalf b. SecondHalf
4. Use logic as $$RC/2 <= NEXTVAL and $$RC/2 > NEXTVAL inside those groups resp.
5. Connect those groups to target instances.

Now the main challenge is to get the RecordCount of previous session to new mapping variable.
Informatica 8.6 has facility wherein you can assign value of Workflow Variable to Mapping Variable and vice versa.
In first session, at components tab there is an option "Post session on successful variable assignment" where we have assigned value of Mapping Variable to Workflow Variable.
In second session, at components tab there is an option "Pre session variable assignment" where we have assigned value of workflow variable to another mappings mapping variable. This is how, we have assigned a value of one mapping variable in mapping 1, to another mapping variable in second mapping.


2 comments:
These interview helped me at right time. Will be handy for my interview next week. thanks Informatica Online Training
Helpful blog, share more like this.
Informatica course in Chennai | Informatica Training center in Chennai
Post a Comment